How our Story Tech Stack helps deliver journalism to 1,000+ local news organizations



Local storytelling has always been in our DNA, but recent investments in our core technology have allowed us to produce something relatively novel: an automated storytelling tech stack for transforming data into full stories—featuring national, state, city, county, or even zip code-level insights for our local news partners at scale.
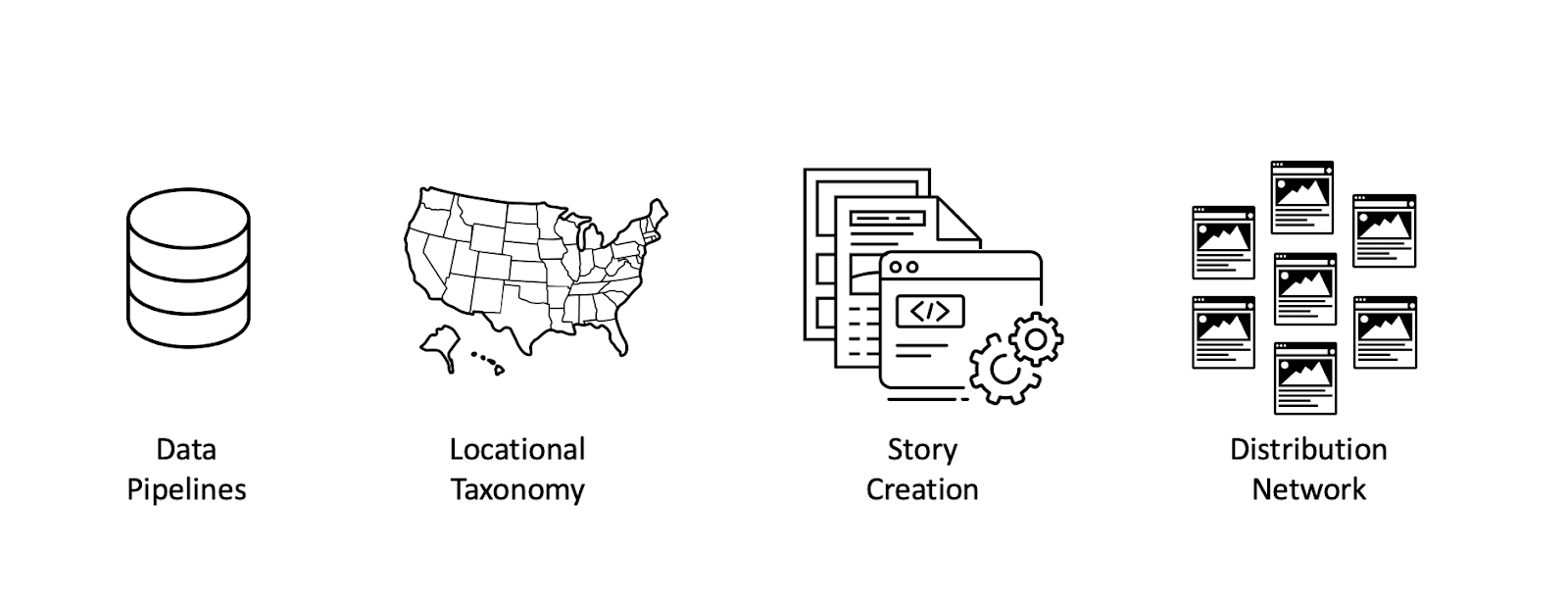
In this post, we’ll walk through how we’re doing it: explaining the 4 elements of our Story Tech Stack that allow us to deliver a range of data-driven stories to our news partners each month.
The ultimate goal of this technology stack is to deliver compelling data journalism for under-covered locations and subject matter—and do be able to do so for partners ranging in size from national networks (like Hearst, Tribune, Lee, Nexstar, and Advance Local) to regional and independent organizations (like Las Vegas Review Journal, Auburn Examiner, Boone Newspapers). Our research and editorial team invests dozens of hours in producing stories that can then be accessed in minutes by reporters and editors—helping fill coverage gaps, inspire new stories, and allow them to engage their audiences in new ways.
Our stories span evergreen national features on women’s history and waste management to local series on historical immigration (available as localized stories for all 50 states), national parks (available for all 364 U.S. MSAs), rural hospital access, job migration, beer rankings, and more. As we look to 2022, we are thrilled to invest more in new data sources, storytelling approaches, and partnerships to produce high-impact stories that can resonate for our network of readers—all supported by the platform we’ve been building since 2017.
#1. Data Pipelines
Over the past four years, we’ve built out data partnerships and pipelines for hundreds of data sources to power our storytelling and streamline production.
We initially focused on getting a baseline of U.S. government data sources ingested into our storytelling platform. The U.S. public data scene is a rich one for journalists. Thirteen organizations making up the Federal Statistical System of the United States, well-known data-collecting agencies like the Bureau of Labor Statistics for economic and cost of living data and the National Agricultural Statistics Service within the USDA. Then you have numerous sub-agencies within broader federal departments—like the National Oceanic and Atmospheric Administration— a treasure trove of historical weather and climate data available at a range of local cuts—which is actually nested within the Department of Commerce.
Beyond government sources, we work with private companies that have rich proprietary datasets, working with partners like Realtor.com (real estate listings), TripAdvisor (restaurants), and Niche (college and place comparisons) to bring new data into the journalism sphere.
Lastly, we work with data from non-profits to feature important data and causes. Stories built on insights from CharityNavigator, Feeding America, and The Conversation offer serviceability and clear avenues for audiences to extend the impact of the story.

#2. Location Taxonomy
Once we have a baseline of rich data sources to power storytelling, the next layer is our taxonomy of geographic locations that align with our ultimate end users: local news organizations.
Initially, we started with a basic locational architecture for all 50 states and 384 metropolitan statistical areas (commonly referred to as MSAs or metros). States were an intuitive starting point for building our taxonomy, while MSAs align with how many news organizations perceive their coverage area and readership. By mapping all MSAs, we can cover roughly 80% of the U.S. population, while our state stories obviously offer something for everyone in America.
The next iteration of our taxonomy was mapping locations within their larger regions (i.e. zip codes, counties, and zip codes within larger MSAs and states), for example mapping all 3,006 counties, 41,692 zip codes, and numerous Census Designated Places to states and MSAs. This level of granularity allows us to expand our story capabilities and look at areas in new dimensions, for example building stories on the priciest zip codes in Boston MA or the counties with the highest rate of COVID-19.
Lastly, we’ve started to map non-geographic entities to our locational taxonomy—think NFL teams, national parks, and colleges—opening up even more storytelling.
#3. Computer-Assisted Story Creation
Our story creation platform leverages automated workflows, editorial review stages, and a custom CMS (content management system), that allows us to integrate newsroom strategies with technology to create, upload, and publish stories at scale. This might seem trivial to someone who hasn’t worked in a newsroom, but the manual packaging of all the writing, data, and photos in a ready-to-publish format is often handled by an army of producers or journalists themselves–requiring a lot of repetitive effort and opening up the chance of human error.
Like most newsrooms, when we started out it took about 2-3 hours of manual effort just to add a single story in our CMS—employing a team of associate editors to add the paragraph blocks, images, and formatting necessary for publication. If we wanted to do that for a full local series for 384 metros… well we just wouldn’t even try.
Now, once we have the edited research and writing that forms the heart of the story, it takes less than 5 minutes to upload and publish each story series for distribution—whether a national feature with 100 slides of images and copy or a local project with separate stories for every state.
Our workflows
Our research team leverages coding languages suited to data analysis (Python, R) as well as proprietary no-code tools to allow subject matter experts to transform data into rankings and analysis that form the framework for each story—culminating in a “prompt” (data brief) that contains all the critical elements of a story.
From there, our custom story workflow allows asynchronous data analysis, writing and editing, and photo/data visualization packaging within our custom Google Docs framework, allowing writers and editors to collaborate seamlessly in the environment they know best.
After building a draft of a story, we leverage an automated ingestion system and custom Drupal CMS that parses through the editorial assets and compiles them in a single CSV that can be uploaded in less than 5 minutes—ready for a final editorial review before publication. No more laboriously copying and pasting text, images, and metadata into the CMS for hours just to package a story—our tech-enabled newsroom is freed up to focus their efforts on the creative, value-add elements of journalism.

#4. Distribution Network
We share our stories to a wide range of news organizations, spanning content portals to national-local networks to local independents.For each partner, we’ve developed streamlined tools for publishing our stories that best align with their technical capabilities and content strategy goals. Drawing on 8 years of experience working with news organizations during his time at the Associated Press, Ken Romano (our VP of Distribution) has built a system for delivering stories to publishers of all sizes and CMSs.
Story Feeds are our primary channel for delivering stories, which are integrated directly into the CMSs of our news partners to allow streamlined story delivery. Available in RSS, JSON, XML formats, we’ve built a technical infrastructure that allows us to set partner specific preferences to customize story format (slide show or single-page), vertical, publishing cadence, image preferences, special character encoding, and other customizations to seamlessly ingest and publish our stories. This was a massive lift over the last several years, typically taking six months to a year for legacy CMSs initially, but the investment was worth it as we learned a lot about how to streamline onboarding through documentation, tailored solutions, and multiple delivery options.
For publishers and journalists that might not be able to ingest a feed of content, we offer several access points:
- Republish Button for syndicating individual stories from our site under a Creative Commons license
- Email Alerts that will send you all stories for your location or beats
- Story Hub, a web-based portal for members of the Stacker Publishing Network
All of these delivery options allow streamlined delivery to maximize distribution and impact of our stories. Meanwhile, our partner news organizations are active stakeholders in shaping our content—identifying the topics that resonate best with their readers and offering feedback and requests around where we should expand our future storytelling scope.
Looking ahead
Our Story Teck Stack enables us to hit on two really special forms of synergy.
One is between Stacker and our publishing network, where our local news partners focus on the stories that are essential and specific to their communities, while we offer stories and data assets that can uncover broader data insights, fill coverage gaps, and ultimately round out their offering, boosting engagement and monetization along the way. Our tech stack lets us cover massive data projects in a way that we’re well suited to. The second is our own internal combination of technology with newsroom expertise, taking the best that automation has to offer, scoping how it can supercharge our ability to produce data-driven stories, and applying it in a way that augments that skills of our journalists.
As we continue to increase the breadth and depth of our storytelling, we are excited to scale the tech to empower journalists both in-house and at our partners to focus on storytelling.
A lot of work has gone into building this tech stack, so we thank our news partners for helping provide guiding insights on where to take our platform, and a special thanks to our developers Nathan, Nichole, and Marc at Mythic Digital who have been important stakeholders in the buildout of the Drupal and distribution components.